
The Turning Point: Agentic AI, Inference Optimization, and Society's Next Challenge
December 2024 has been busy with LLM updates and has shown us the path forward

This marks the final post in this series on the impact of AI on society. While circumstance has led to the series concluding now, December 2024 has provided us with a remarkably tangible glimpse into what lies ahead, validating many of the themes explored in previous installments.
What's on the Horizon
Among the recent developments in AI, two1 pivotal shifts have emerged that warrant particular attention:
1. The rise of agentic workflows
2. The evolution of test/inference time optimization
Agentic Workflows

The concept of agentic workflows varies across the industry, but I think Nvidia’s definition captures the broad application space that's gaining momentum:
"[An agent is] a system that can use an LLM to reason through a problem, create a plan to solve the problem, and execute the plan with the help of a set of tools. In short, agents are a system with complex reasoning capabilities, memory, and the means to execute tasks."
This represents a significant departure from the chatbot interfaces that characterized early LLM deployments. Instead of requiring direct human interaction, these systems operate autonomously, executing complex tasks in the background. While still nascent, we're seeing major players like Salesforce pivot strategically to position agents as central to their future vision.
Consider Anthropic's computer use feature – though still in beta with acknowledged limitations, it offers a compelling preview of future agentic systems where LLMs independently operate computers. This shift isn't merely technical; it represents a fundamental change in how AI technologies integrate into workflows.
The timing of this focus on agentic systems is particularly significant. Beyond attracting increased investment and attention, these systems represent a paradigm shift in AI's impact on society. By removing humans from the role of technology orchestrators, pure agentic systems are positioned to be more direct replacements of human labor rather than mere enhancers. They don't just augment existing workflows – they have the potential to automate entire segments of roles previously performed by humans.
This trajectory is increasingly acknowledged in corporate messaging, exemplified by Artisan's provocative "Stop Hiring Humans" campaign. As investment continues to flow toward agentic systems, driving down costs and improving performance, we should expect the immediate financial returns from LLMs to manifest primarily through labor efficiency rather than pure innovation.
Inference Optimization
The second strategic shift centers on test-time/inference compute and reasoning as performance drivers for large foundation models. This trend has been building momentum, marked by OpenAI's o1 release and highlighted in Ilya Sutskever's widely-discussed NeurIPS talk suggesting we're running out of data and will have to look elsewhere for performance improvements.
This culminated in OpenAI's o3 announcement, and notably its performance on the ARC-AGI-12 Challenge. While the current computational requirements make the “high-tuned” approach prohibitively expensive for most applications and ineligible for the ARC Challenge, the trajectory matters more than the present limitations. Additionally the Low-tuned model is within the competition thresholds, and is currently sitting in first place in the competition. Per François Chollet’s write up on the submission “ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.”
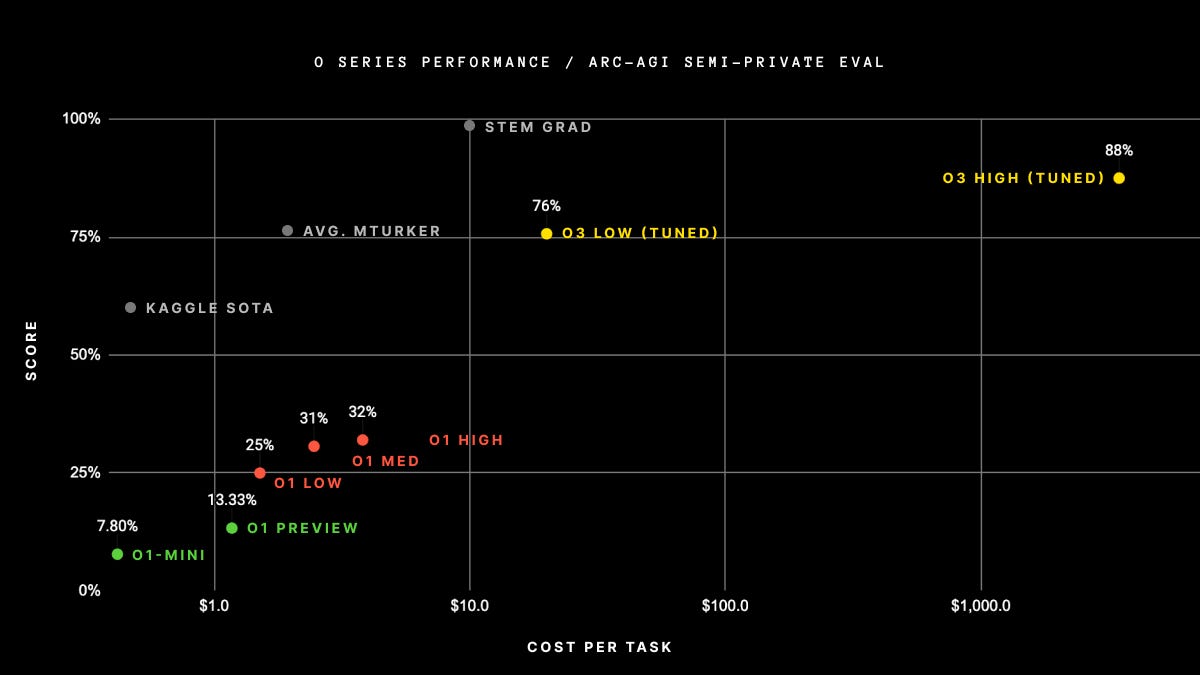
We appear to have identified the essential components needed for meaningful societal transformation through LLM systems, and we're beginning to assemble them effectively. The significance of inference optimization lies in demonstrating that performance gains aren't solely dependent on increased training data – optimization can occur at multiple stages of development.
This has profound implications for both corporate investment strategies and regulatory frameworks. As detailed the previous post in the series, relying on model training compute thresholds as a regulatory mechanism overlooks crucial aspects of LLM development that can drive performance improvements. Test-time performance optimizations effectively circumvent these training thresholds, challenging their efficacy as regulatory tools. While these models still require substantial training compute, the principle of test-time optimization fundamentally disrupts the paradigm of using training compute as a proxy for model capability.
Making Sense of the Path Forward

Our focus should shift to three critical priorities: preparing society for impending changes, implementing logical regulation, and establishing robust measurement frameworks.
We currently risk stifling the positive innovations that LLM-based systems could deliver, not because of technological limitations, but because our society remains unprepared for their implications. Consider the automation of repetitive or undesirable work – this should represent an unequivocal positive development for humanity. However, without viable alternative employment pathways and proper societal adaptations, even these clear improvements become potential sources of disruption.
Even more striking are the domains where human capacity currently constrains critical services, such as mental health care and drug development. These areas represent opportunities where AI automation could dramatically expand access to essential services that are currently bottlenecked by human limitations. Yet, in our current framework, even these universally beneficial applications carry significant downsides – potentially disrupting career paths and reducing earning potential in these industries. This paradox – where objectively positive developments create societal challenges – highlights the urgent need for proactive adaptation.
While AGI remains a valuable metric for tracking developments among frontier model providers, its dominance in being the primary means of evaluating LLM progress in the general lexicon has become problematic. We must recognize that systems need not approach AGI to fundamentally reshape entire professions.
The reality of AI capability development is more nuanced, characterized by what Ethan Mollick’s commentary on the o3 model capabilities. “AGI is going to prove a limited standard to think about because we will have Jagged AGI - superhuman at some tasks, weaker at others. Just because o3 is as good as the 175th best competitive coder on Earth (out of 600,000) doesn’t mean that it is as good as them at every task they do (for now).”
These asymmetric capabilities can have profound societal implications well before we approach anything resembling AGI. The emerging paradigm suggests a future where human oversight of autonomous systems becomes the dominant operational model across diverse sectors. While this human-AI collaboration model is already accepted in certain domains – consider modern manufacturing where workers supervise automated assembly lines – its expansion into knowledge work represents a fundamental shift in how we conceptualize professional expertise.
We need to prepare society not just at an institutional level, but at an individual level for a world where the most efficient workflow often involves humans validating and refining the output of autonomous systems rather than performing tasks from scratch. This transition will be particularly challenging in knowledge-intensive fields where professional identity has traditionally been tied to direct problem-solving rather than oversight and validation.
The path forward hinges on our ability to develop and implement rigorous measurement frameworks. We need domain-specific, empirical methods to evaluate AI systems that go beyond simplistic benchmarks. This isn't merely an academic pursuit – it's fundamental to realizing the full potential of LLMs while maintaining clear visibility into their actual capabilities and limitations. Without concrete measurement frameworks, discussions about AI impact risk devolving into a mixture of anecdotal evidence and emotional reactions, neither of which serves society's interests.
This imperative for empirical understanding has shaped my own professional trajectory. The transformation ahead feels increasingly certain – we've moved beyond debating whether these changes will occur to grappling with their timing and nature. Yet historical patterns of technological adoption remind us that societal change, even when driven by transformative technologies, rarely follows a linear path.
The variable pace of development and more importantly adoption makes timing predictions challenging, but this uncertainty shouldn't breed complacency. By the time widespread adoption becomes obvious, the window for proactive preparation will have closed. We need to act now – whether through developing robust measurement frameworks, advocating for evidence-based regulation, or preparing our institutions for fundamental change. The groundwork we lay today will determine how successfully society navigates this transition, regardless of its precise timeline.
Honorable mentions to open-source catching up to closed source, but I think that is more of a known entity right now, as well as “Sovereign AI” which is likely to be more of a forward-looking trend in the coming years.
The ARC (Abstract Reasoning Challenge) and specifically the ARC-AGI-1 dataset represents a significant benchmark in AI evaluation. Created by François Chollet, it tests AI systems' ability to solve novel visual-logic puzzles that require abstract reasoning and pattern recognition. The ARC test questions are fundamentally different from the training data, meaning systems can't rely on pattern matching or memorization – they must demonstrate genuine abstract reasoning capability.